NLP Scam Call Detector

In July, my grandmother received a phone call from an unknown number. The caller claimed to be her grandson, telling her that he was arrested and needed $5000 for bail. Unfortunately, she believed this caller to be me initially, but she knew something wasn’t right. Distressed, she texted me to see if the story she heard was true, and I was able to clear everything up for her and warned her about these types of malicious scams. This inspired me to find a solution for this problem; after searching through some research papers, I found a paper which was able to accurately detect a scam conversation using Natural Language Processing and the k-means clustering algorithm. Using this paper as a resource, I created my own version of the project.
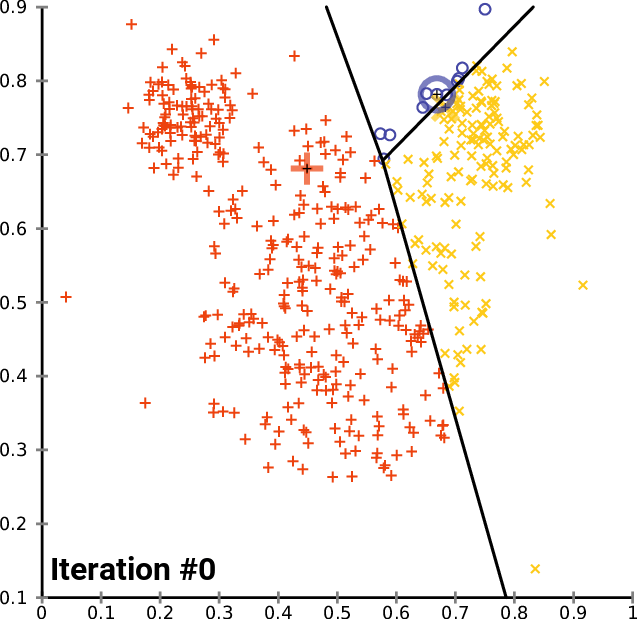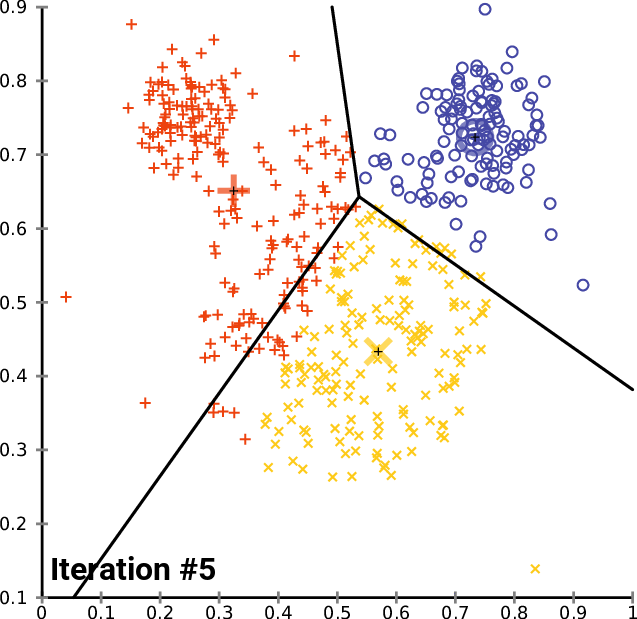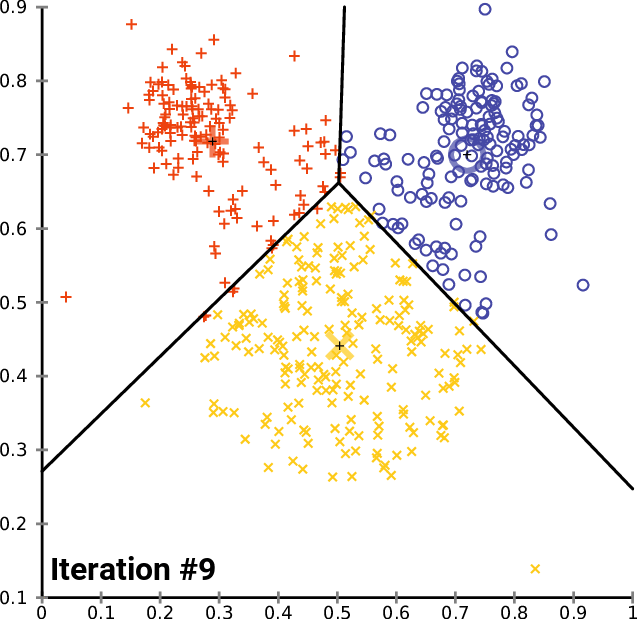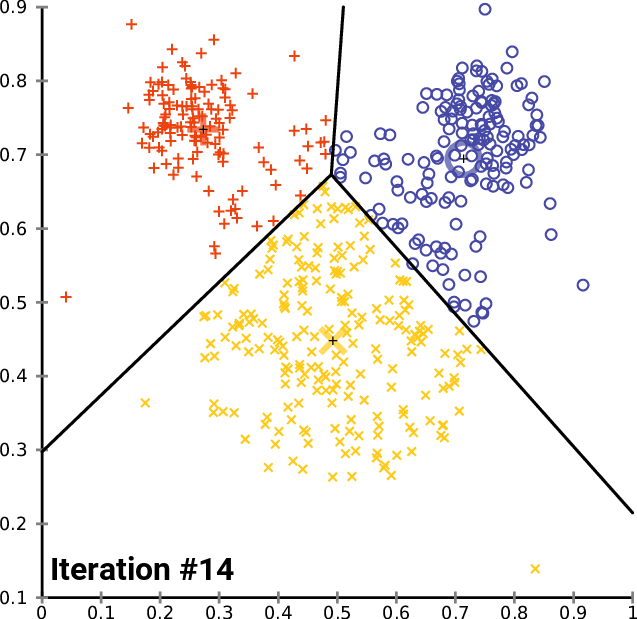
To train the model, I used the same dataset as the researchers. It consisted of an Excel spreadsheet containing scam conversations in each column, alternating between the dialogue of the scammer and the victim in each row. Using the Pandas library, I imported each conversation into a Python array, processing them so that each conversation is split into sentences. Using Google’s Universal Sentence Encoder pre-trained transformer model, each sentence was then encoded into a 512-dimensional vector representing their semantic meaning.
Now, with a set of vectors which represent sentences from scam calls, I used the k-means clustering algorithm to find regions in the vector space which are most likely to be scam related. The algorithm provides the centroids for each cluster, which can be thought of the average semantic meaning of a scam related sentence.
Finally, new input sentences were compared to the centroids by encoding them and taking the inner product between the new vector and each of the calculated centroids. If the semantic meaning of the new sentence is close enough to average semantic meaning of any of the scam calls, a value close to 1 is returned by the inner product. Through experimentation, I found values near 0.65 were typically able to identify scam calls accurately without triggering too many false detections (i.e. a non-scam sentence is classified as a scam).
This was my first solo machine learning project, and I was able to experiment with many different techniques for the first time. This is the first time I had to clean and process data, learning how to use Pandas to import the conversations to my Python code. I applied the linear algebra understanding I’ve gained through school to learn how sentence embeddings work, also learning what it means to take the inner product of two vectors in a high-dimensional space. Having the research paper as a resource was very helpful, pointing me in the right direction to solve this problem without using anyone else’s code (aside from importing the Universal Sentence Encoder from Tensorflow Hub).